Sharing data with the world
The database of publicly known vulnerabilities and exploits affecting IoT devices has been developed at NASK. The entire process of the database creation can be divided into the following steps:
- Identification of the data sources,
- Collection of the data from the selected sources,
- Data aggregation, correlation and enhancement
- Filtering of the data concerning IoT
- Publication of the data
The process is visualised in the graph below and will be further explained in the following part of this article.
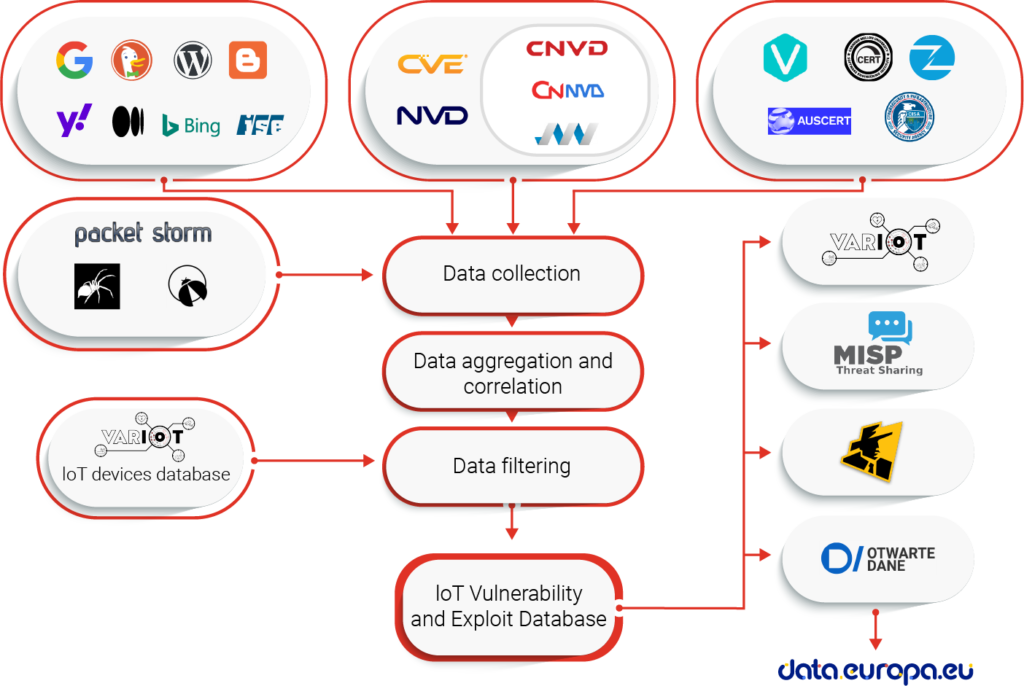
Data acquisition and processing
The first step – identification of the data sources – was solved twofold. Firstly, we searched the web manually to find sources of information about vulnerabilities and exploits, especially of IoT devices. They can be divided into 4 main categories:
- National vulnerability databases, such as NVD or JVNDB,
- Structured sources related to the security industry, focused on vulnerabilities, such as security advisories from CERTs, bulletins of product vendors or bug bounty programs, commercial databases and aggregation services,
- Sources focused on exploits, like exploit-db,
- Other sources – websites and blogs created by small groups of enthusiasts or individual researchers.
Sources from the first three categories contain well structured data and are used directly as primary sources for Vulnerability and Exploit databases. Currently used vulnerability information sources are:
- National Vulnerability Database (NVD),
- China National Vulnerability Database (CNVD),
- Chinese National Vulnerability Database of Information Security (CNNVD),
- ICS Vulnerability Database (IVD),
- SecutiryFocus Bugtraq (BID)*,
- Japan Vulnerabilities Notes Database (JVNDB),
- Packet Storm Security,
- Carnegie Mellon University CERT Coordination Center,
- VUL-HUB,
- Vulmon Vulnerability Search Engine,
- Zero Day Initiative (ZDI),
- Zero Science Lab (ZSL)
*indicates sources that were used during the development and are included in our data, but are no longer available.
The vulnerability information sources are discussed in greater detail in our published article: https://www.mdpi.com/1424-8220/20/21/5969/htm
Exploit sources included in the VARIoT database are:
- Exploit Database by Offensive Security,
- SecutiryFocus Bugtraq (BID)*,
- Packet Storm Security,
- exploit-database.net*.
*indicates sources that were used during the development and are included in our data, but are no longer available.
The sources can dynamically change – some of them have already disappeared during development of our databases, while new ones may be created. Therefore, the databases are created in a way that allows easy addiction of new sources.
The processing of data from the source databases is shown below:
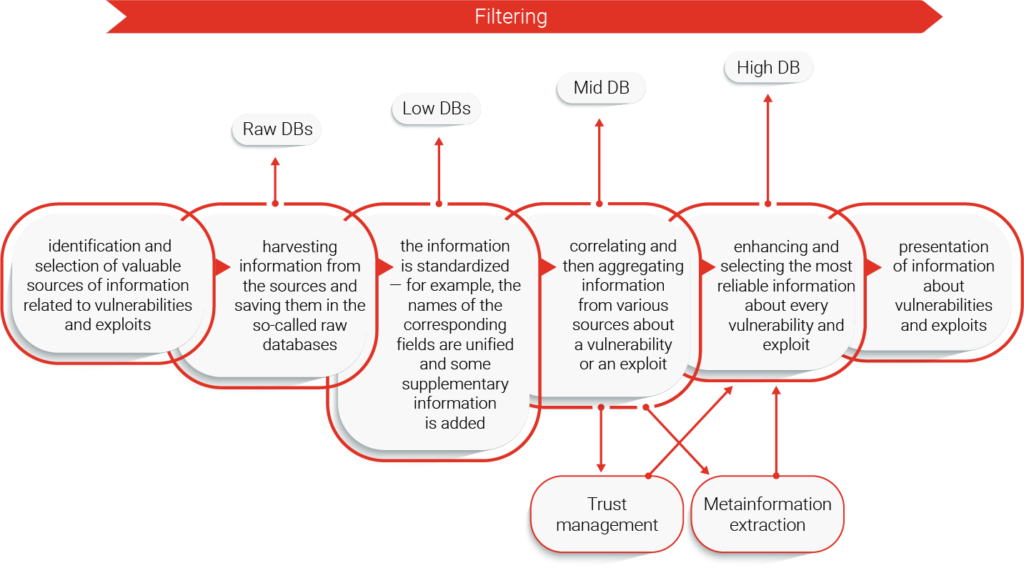
Data harvested from each source is saved in Raw databases. They are unique for each original source and are designed to keep all the information available from their corresponding source. Data from non-English sources are translated to English before further processing. We have developed two common formats for the data received from various sources – one for exploit, and one for vulnerability entries. Data from the Raw databases is adapted to fit within it, which results in creation of Low databases – while they are still separate for each individual source, they store data in a unified format. This data is then aggregated in two independent Mid databases, for vulnerabilities and exploits. Each Mid database entry connects entries from different sources that describe the same vulnerability or exploit. Mid databases are used to create the High databases, which contain the most reliable information available from the original sources. Data filtering occurs during the High database creation, as only IoT related entries are allowed into the High databases. The in-depth description of the entire process, from data harvesting to creating High databases was published in https://www.mdpi.com/1424-8220/21/13/4359/htm.
Sources from the first three categories contain a substantial amount of data, usually provided in a way that is friendly with the automatic data harvesting. However, information about many vulnerabilities and exploits never reach these sources, but they can be found within other, unstructured sources from the 4th category. They are scattered around the Internet, and although most of them individually contain only a handful of data, their total share of interesting information is significant. As these sources are numerous and volatile in nature, we need another approach to discover and harvest them. To do this, we created a web search engine tailored to find information about IoT vulnerabilities and exploits. It is using search engine APIs from Google, Bing, Yahoo! and DuckDuckGo. We have developed a trust evaluation method, which lets us find the most appropriate pieces of information among the search results. The results obtained from this tool are enriched through a metainformation extraction mechanism using NLP and ML/AI techniques, which lets us search for related entries in the vulnerability and exploit databases. These enriched entries are publicly available as the IoT device security news feed on the variotdbs.pl website. The entire process is visualized below:

Data sharing
The information from our databases is publicly available on the dedicated website: https://www.variotdbs.pl/. The website may be displayed in either English or Polish language, which can be changed at the bottom of the page.
Data is organised in three independent sections:
- Vulnerabilities, which shows vulnerabilities that affect IoT devices,
- Exploits, with publicly available exploits that target IoT devices,
- News, an automatically generated news feed with the latest information about IoT vulnerabilities.
The Vulnerability section shows vulnerabilities affecting IoT devices. It lets you browse the latest IoT vulnerabilities and search the database. Each entry consists of data about a given vulnerability found in different sources. The entries format is described in detail in vulnerability entry ontology: https://www.variotdbs.pl/ref/variotentry/. Similarly, the Exploit section presents exploits that can threaten IoT devices.
News section lists recent articles about IoT vulnerabilities, found automatically using Internet search engines. An NLP mechanism helps assigning trust values and vulnerability types to each news item. Related IDs from external vulnerability and exploit databases are listed with each entry. If there is any VARIoT database entry related to the same vulnerability or exploit found, its ID will also be displayed on the list.
Vulnerabilities and Exploits are also accessible using an API. We encourage you to register on our website and try our API out. Access instructions can be found on https://www.variotdbs.pl/api/. The data may be received in a regular JSON format or as JSON-LD. The data published in the latter is also available through the data.europa.eu portal and Polish Open Data Portal.