Creation of IoT Vulnerabilities and Exploits Databases
In this post we show our approach and recent advancements in the creation of vulnerabilities and exploits databases (Activity 1 of VARIoT) and the data correlation and aggregation (Activity 3 of VARIoT).
The database of publicly known vulnerabilities and exploits affecting IoT devices is being developed at NASK. The entire process of the database creation can be divided into the following steps:
- Identification of the data sources – done (constantly updated)
- Collection of the data from the selected sources – in progress
- Filtering of the data concerning IoT- in progress
- Data aggregation, correlation and enhancement – in progress
- Publication of the data – planned
Our current advancements in this process are visualised in the graph below and will be further explained in the following sections of this article.
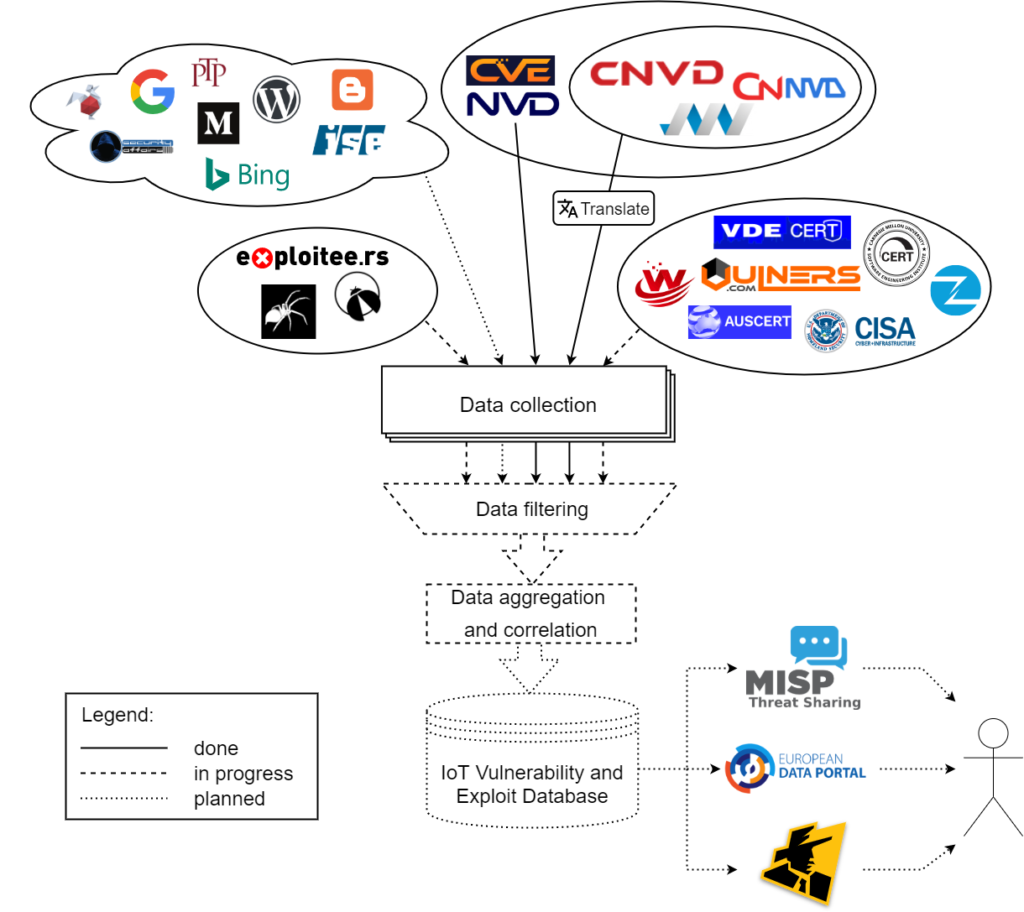
The first step – identification of the data sources – is solved twofold. Firstly, we searched the web manually to find sources of information about vulnerabilities and exploits, especially of IoT devices. They can be divided into 4 main categories:
- National vulnerability databases, such as NVD or CNNVD,
- Structured sources related to the security industry, focused on vulnerabilities, such as security advisories from CERTs, bulletins of product vendors or bug bounty programs, commercial databases and aggregation services such as Vulners, etc.,
- Sources focused on exploits, like exploit-db, exploitee.rs,…
- Other sources – websites and blogs created by small groups of enthusiasts or individual researchers.
The first three categories contain a substantial amount of data, usually provided in a way that is friendly with the automatic data harvesting. However, information about many vulnerabilities and exploits never reaches these sources, but they can be found within sources in the 4th category. They are scattered around the Internet, and although most of them contain only a handful of data, their total share of interesting information is significant. As these sources are numerous and volatile in nature, we need another approach to discover them. To do this, we will use a web search engine tailored to find information about IoT vulnerabilities and exploits. This is achieved by using both Google and Bing search APIs. Our tool has two modes of operation – in the first one the user has to provide a name of the IoT device and receives only the results about vulnerabilities and exploits affecting it. In the second mode, the tool searches for information about any IoT device. Its intended use is to automate the process of discovering new sources and new information.
With the first step completed, we are able to use its outcomes in the second one. The current progress of work is visualised in the picture – the sources connected to our data collection hub with solid lines are already continuously harvested, while we are actively working on developing mechanisms for gathering data from the sources connected with dashed lines. The sources with dotted lines are under consideration to be added in the future. As you can see in the picture, data from every primary source (e.g. national vulnerability databases) are already included in our system. For national databases other than NVD, their entries have to be translated to English. This is done in an automatic way, using Google Translate API. Some additional sources are already handled, most notably ZDI and Vulners. We are still working on implementation of the remaining individual sources and mechanisms for retrieving information from blogs and websites, but the progress in this area has recently slowed down as we started working on step 4 – data aggregation and correlation – and now we are doing both tasks simultaneously. The step 3 requires advancements both in the previous step, and in the IoT device cataloguing. They will let us choose only entries with vulnerabilities and exploits affecting IoT products to be put into the database.
To accomplish step 4, we have developed a common format for the data received from various sources and adapted the already obtained information to fit within it. Currently, our main effort lies in creating the mechanisms of data aggregation and correlation, which will let us unite all entries regarding the same vulnerability originating from different sources in a single record. Each record will receive its unique identifier. All records will contain references to identifiers from sources. For every record containing data from multiple sources the information quality will be assessed which will affect the aggregation results. Finally, data will be shared within step 5 through the European Data Portal, MISP Threat Sharing Platform and Shadowserver’s free daily remediation feeds. This public data feed is planned to be available in June 2021.
The blog post was co-sponsored by the program of the Minister of Science and Higher Education entitled ”PMW” in the years 2020–2022; contract No. 5095/CEF/2020/2